背景
尝试搭建这个服务本来是运维的事情,可是技术主管说这个东西需要技术来搞一搞。公司内部的服务器端的应用模块存在过多,一个完整业务流程需要涉及到多个应用模块,这样在线上排查日志,日常应用开发时的调试都造成了一定的麻烦。而且由于业务的特殊性,日志汇集到中央日志服务器是必要要做的。
需求
日志汇集在考虑有效的基础上,也需要考虑中央日志服务器的负载,所以在借鉴传统LK方式基础上引入kafka,也是此服务搭建不同于传统日志汇集的地方。filebeta日志采集工具的资源消耗较少比较轻量级也是选型的结果。
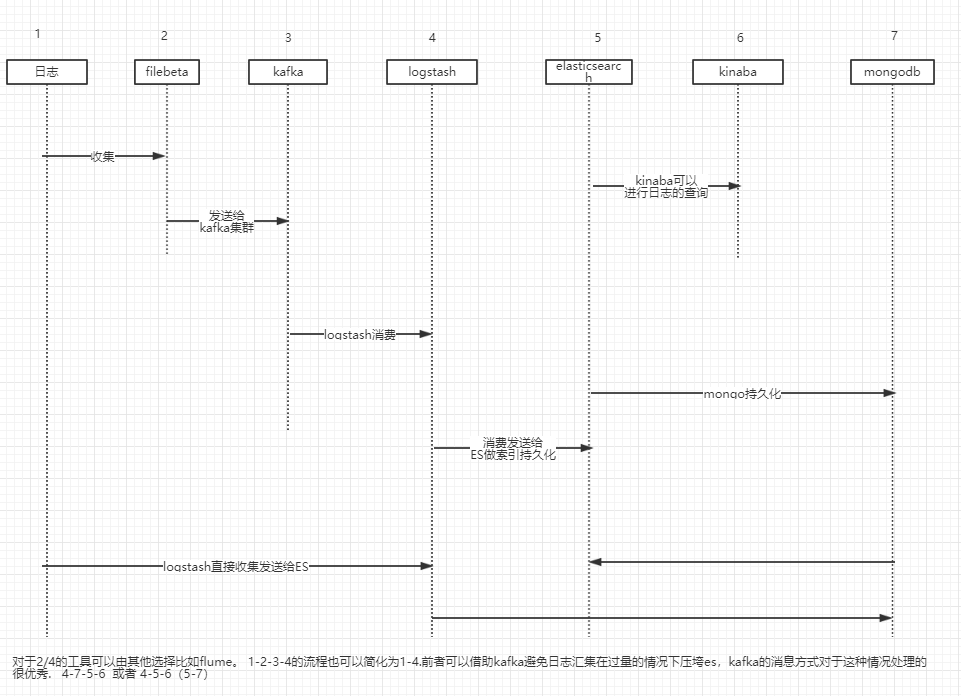
** 此流程只是跑通了以上的所有系统,对于日志具体采集过滤等需求此文没有深入讨论 **
环境搭建
lszrz 安装
yum -y install lrzsz
screen安装
# http://man.linuxde.net/screen
yum install -y screen
supervisor安装
# https://www.cnblogs.com/zhoujinyi/p/6073705.html
yum install supervisor
mogondb
下载与解压
curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz # 下载
tar -zxvf mongodb-linux-x86_64-3.0.6.tgz # 解压
启用
# screen
mongod --dbpath=/data/db/
ctrl+a+d
参考
#https://blog.csdn.net/wangli61289/article/details/44459467
elasticsearch
安装
# wget / curl url 下载
[root@VM_187_61_centos elasticsearch]# ll
total 89380
-rw-r--r-- 1 root root 91429350 Jul 14 21:10 elasticsearch-6.3.1.tar.gz
[root@VM_187_61_centos elasticsearch]# pwd
/data/elasticsearch
[root@VM_187_61_centos elasticsearch]# tar -xvf elasticsearch-6.3.1.tar.gz
配置
elasticsearch.yml
# config下
cluster.name: logindex
node.name: lognode
path.data: /data/elasticsearch/elasticsearch-6.3.1/data
path.logs: /data/elasticsearch/elasticsearch-6.3.1/logs
network.host: 0.0.0.0
http.port: 9200
jvm.options
-Xms1g
-Xmx1g
运行
elasticsearch 不能以root用户运行
# /data/访问权限读写全开
chmod 777 -R /data/
# 添加用户
useradd viakiba
# 设置用户密码
passwd viakiba
# 切换用户
su viakiba
# 启动
./elasticsearch
trouble shoting
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
处理方式
# 切换到root用户修改配置sysctl.conf
vi /etc/sysctl.conf
# 添加下面配置
vm.max_map_count=655360
sysctl -p
#然后启动elasticsearch
#访问 http://ip:9200/
kibana
安装
# 下载 wget/curl
# 解压
tar -xvf kibana-6.3.1-linux-x86_64.tar.gz

配置
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://localhost:9200"
启动
screen -S kibana
./kibana
ctrl+a+d
访问
# http://182.254.152.232:5601
# 使用在后面
Kafka
安装
# 下载 wget/curl
# 解压
tar zxvf kafka_2.12-1.0.1.tgz
# kafka里面包括的有一个zookeeper注册中心 目前使用此注册中心进行注册
配置
zookeeper
dataDir=/data/kafka/zkdata

Kafka
# log
log.dirs=/data/kafka/kafka_2.12-1.0.1/logs/kafka-logs
# zk地址
zookeeper.connect=localhost:2181
# kafka端口号
listeners=PLAINTEXT://:9092
启动
zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
Kafka
bin/kafka-server-start.sh config/server.propertiessh
验证
#创建topic
kafka-server-start.sh config/server.properties
#列出topic
kafka-topics.sh --list --zookeeper localhost:2181
filebeta
安装
#下载与解压
#wget/curl
tar -xvf filebeat-6.3.1-linux-x86_64.tar.gz

配置
filebeta.yml
** 这里监控elasticsearch下的日志作为实验对象 **
filebeat.inputs:
- type: log
enabled: true
paths:
/data/elasticsearch/elasticsearch-6.3.1/logs/*.log
exclude_lines: ['^DBG']
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
output.kafka:
enabled: true
hosts: ["127.0.0.1:9092"]
topic: "test"
# 记得注释默认的 output.elasticsearch以及次级配置
启动
# screen
.filebeat
验证
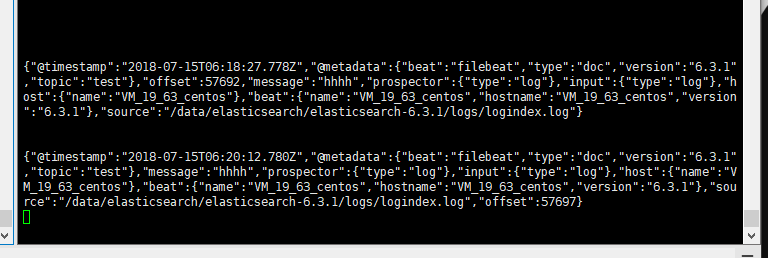
启动消费者
# 消费者
/data/kafka//kafka_2.12-1.0.1/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
模拟生产者写入log记录
# 生产方式 写入log
echo 'hhhh' >> /data/elasticsearch/elasticsearch-6.3.1/logs/logindex.log
logstash
安装
# wget/curl
unzip logstash-6.3.1.zip


配置
kafka-logstash-es.conf
input {
kafka {
bootstrap_servers => "127.0.0.1:9092"
topics => ["test"]
codec => json
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "test"
}
stdout{
codec=>json
}
}
启动
[root@VM_19_63_centos bin]# ./logstash -f ../config/kafka-logstash-es.conf
参考
https://blog.csdn.net/weixin_38098312/article/details/80181415
https://blog.csdn.net/weixin_38098312/article/category/7615665